 From a service delivery perspective a thing which is more frightening than having a major outage is the potential that the issue could happen again if we don’t do proper post incident reviews after service is restored.
From a service delivery perspective a thing which is more frightening than having a major outage is the potential that the issue could happen again if we don’t do proper post incident reviews after service is restored.
Call it whatever you want to; severity one, priority one or major incident, when service is adversely impacted, you need to make sure that it is restored as quickly as possible. while you are doing this however, it is important to make sure that you are collecting all the information you need to ensure you can learn from this experience to assist in the future prevention of this type of incident.
Having worked on more critical incidents than I care to remember, there is a common flow on how they operate. In the initial stage there is a sense of “is this an issue?” people are escalating information that may or may not relate to the current situation. While it may seem like a major issue it might be tougher to separate the real deal from some side effects.
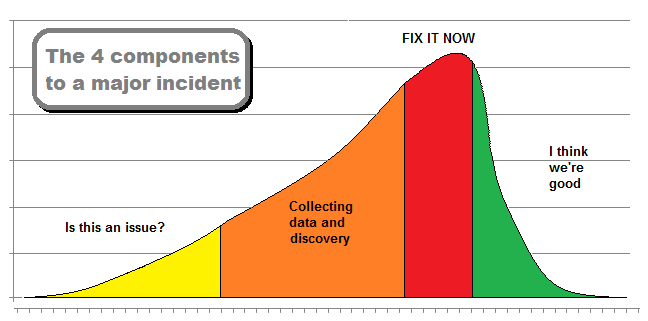 The second stage is the collecting data and discovery phase where we are starting to get a sense that the issue is real and is impacting a wide majority of people. We are able to confirm through various escalation points this is indeed happening and we have started (hopefully) to gather some support resources to assist.
The second stage is the collecting data and discovery phase where we are starting to get a sense that the issue is real and is impacting a wide majority of people. We are able to confirm through various escalation points this is indeed happening and we have started (hopefully) to gather some support resources to assist.
The third stage is what I like to call “Let’s fix this NOW”. The drivers for this may be the criticality of the service in question or an agreement of some type. It might also be driven by someone (usually at the top) doing the gargoyle over the incident command center.
The final stage is where we have resolved the incident but are looking for confirmation that it is truly restored, or the I think we’re good stage. It is in this stage where we should schedule a post incident review. It is also important at this time while the issue is being verified as resolved that the incident record is as current as possible. This way when we do the review we have all the information we can to ensure we can make the most of this.
Here is the challenge, in a culture which celebrates firefighters we want to make sure we do go back and do the post incident review in the first place. It is very easy to say we will and then another crisis appears and it gets postponed indefinitely.
The next challenge is to make sure that we have enough information to see what went well and not so well during the investigation. Did we have the right resources, what areas did we check. Could improvements be made on the investigation and diagnosis end for next time should it arise?
If what we did to correct the issue was a system change (I am sure an emergency change was recorded) than is there anything we need to adjust to other systems to ensure they are stable. If this incident was the result of a change what can we learn from that.
Remember, the review should have all parties who were involved in the incident as well as keeping people who are related to the support of the service equally as informed. Just because the application delivery team was not part of the restoration process does not mean they do not need to be informed on a service they also support.
The post incident review should also be kept as a knowledge record which is accessible to all appropriate stakeholders. Any action items which were identified in the review should have a timeframe and be validated as completed. There isn’t much point on reviewing if you aren’t going to follow up on them.
To ensure we are able to provide service we must be sure that we not only have a way to restore issues should they occur but have an equally good method of ensuring issues don’t happen a second time.